About Me
I am a final-year PhD candidate at the University of Alberta, supervised by Dr. A. Rupam Mahmood and Dr. Dale Schuurmans.
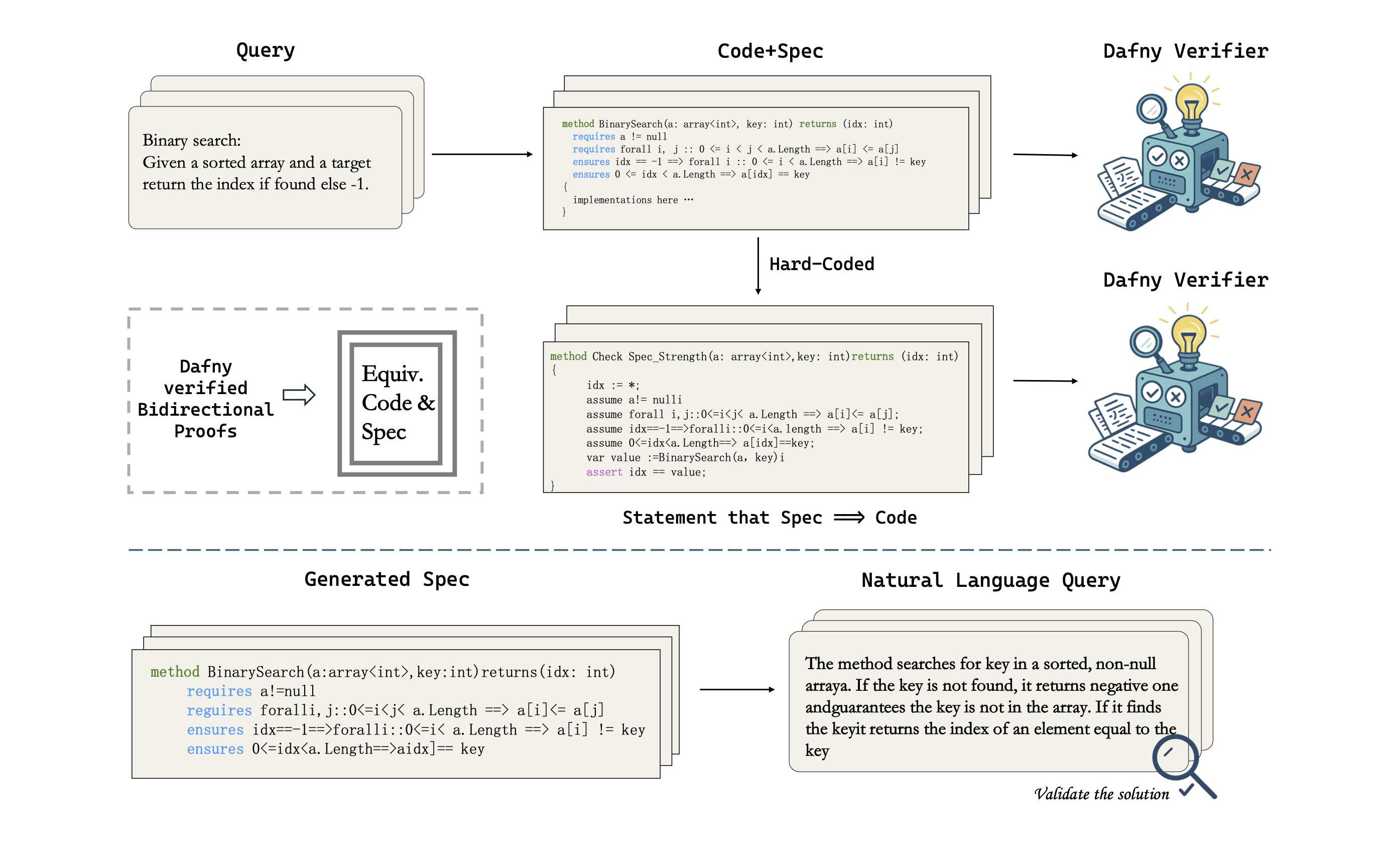
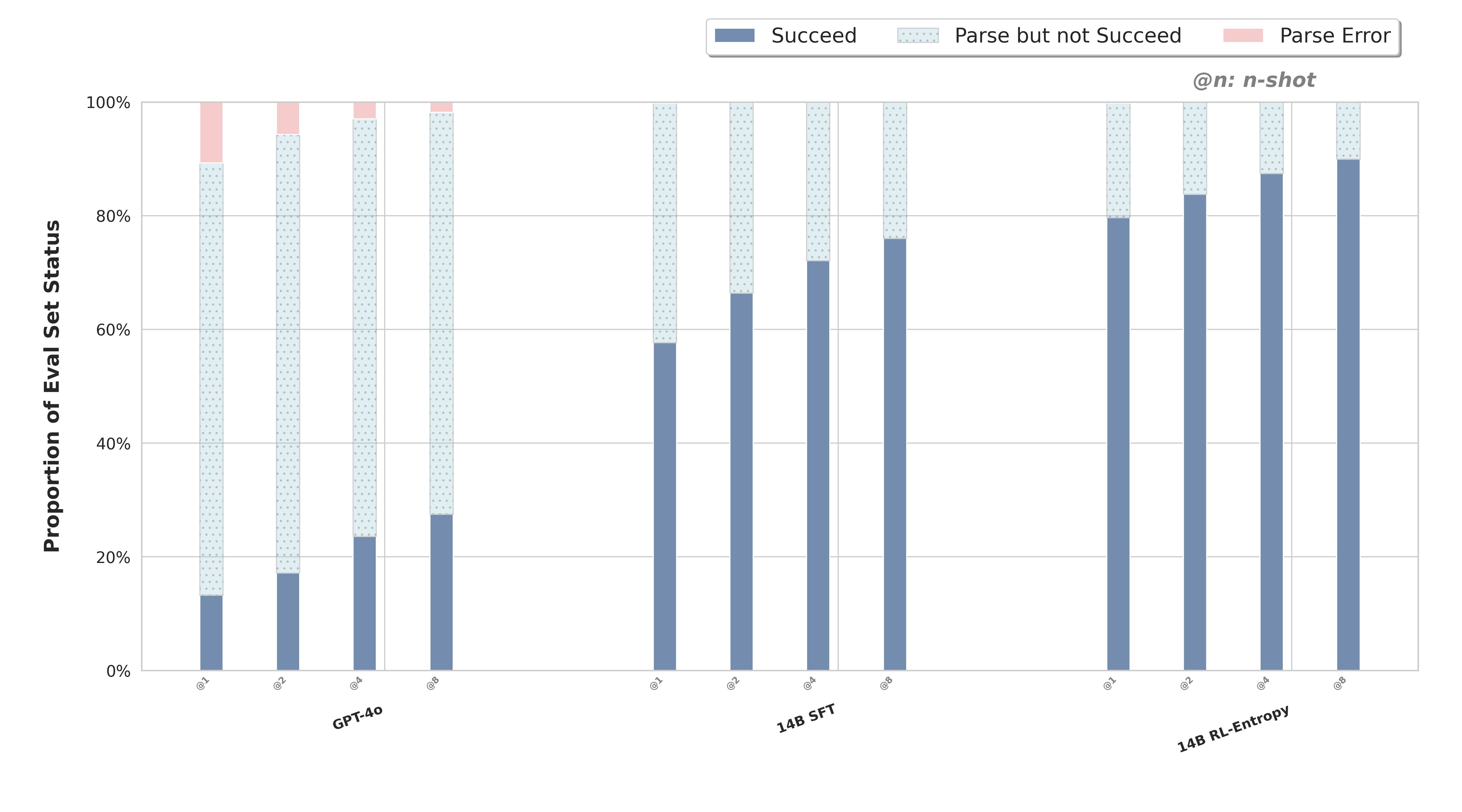
I’m currently developing verifiable coding agents that can formally guarantee alignment between agent behaviour and user intentions. This trend of work targets a fundamental challenge in AI safety: ensuring that autonomous systems execute tasks transparently, without unexpected or unverified behaviours.
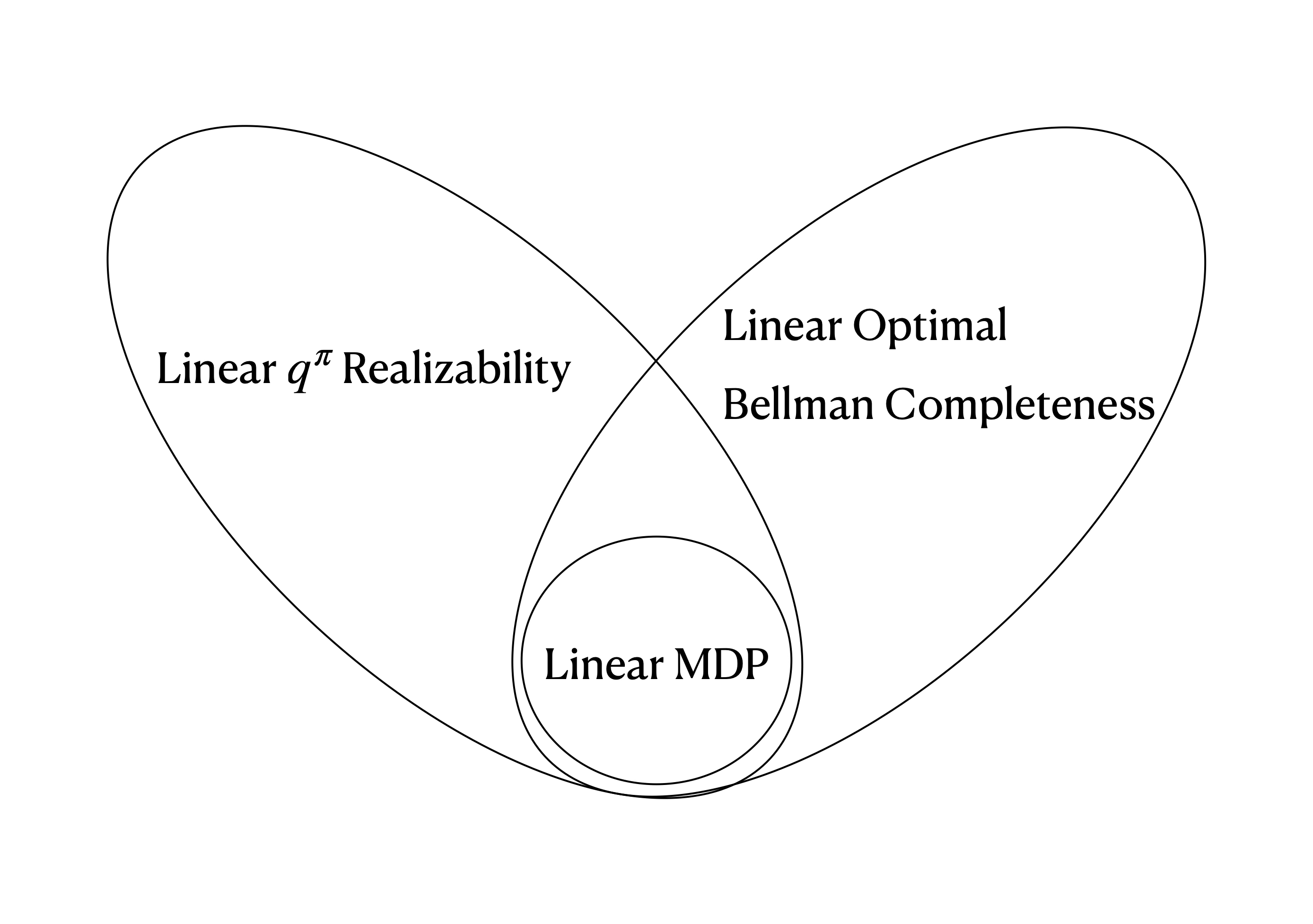
I used to work on effectively using data for reinforcement learning. I design and analyze algorithms that leverage datasets experiencing distribution shifts and investigate how data should be collected. My research philosophy centers on understanding empirical problems from a theoretical perspective and guiding algorithm design with theoretical insights.
News
2025.10: Fengdi received the Verna Tate Graduate Scholarship in Science and began her internship at Netflix in Bay area!
2025.02: Our tutorial “Advancing Offline Reinforcement Learning: Essential Theories and Techniques for Algorithm Developers” is accepted at AAAI 2025, Philadelphia, PA, hosted by Fengdi Che, Chenjun Xiao, Ming Yin, and Csaba Szepesvári!
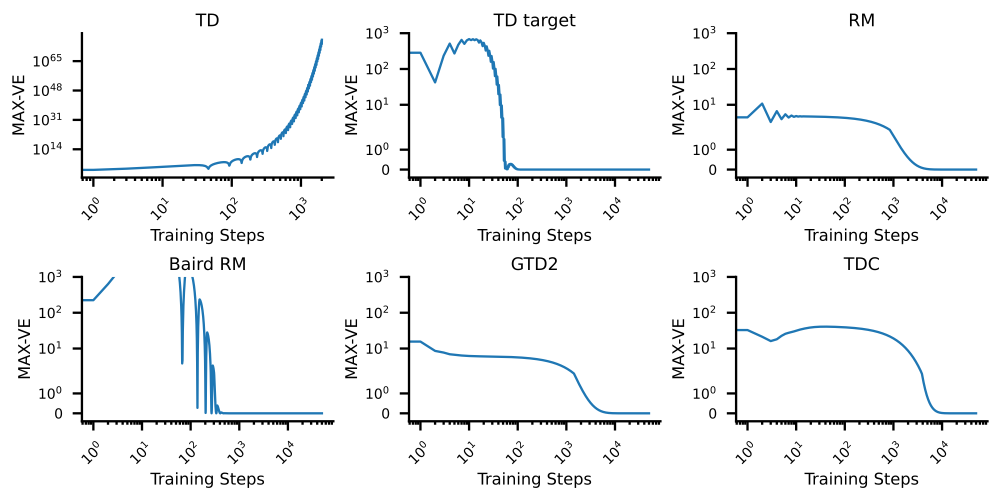
2024.07: Our paper “Target Networks and Over-parameterization Stabilize Off-policy Bootstrapping with Function Approximation” is presented at ICML 24 as a spotlight paper with only a 3.5% acceptance rate.
Key Publications